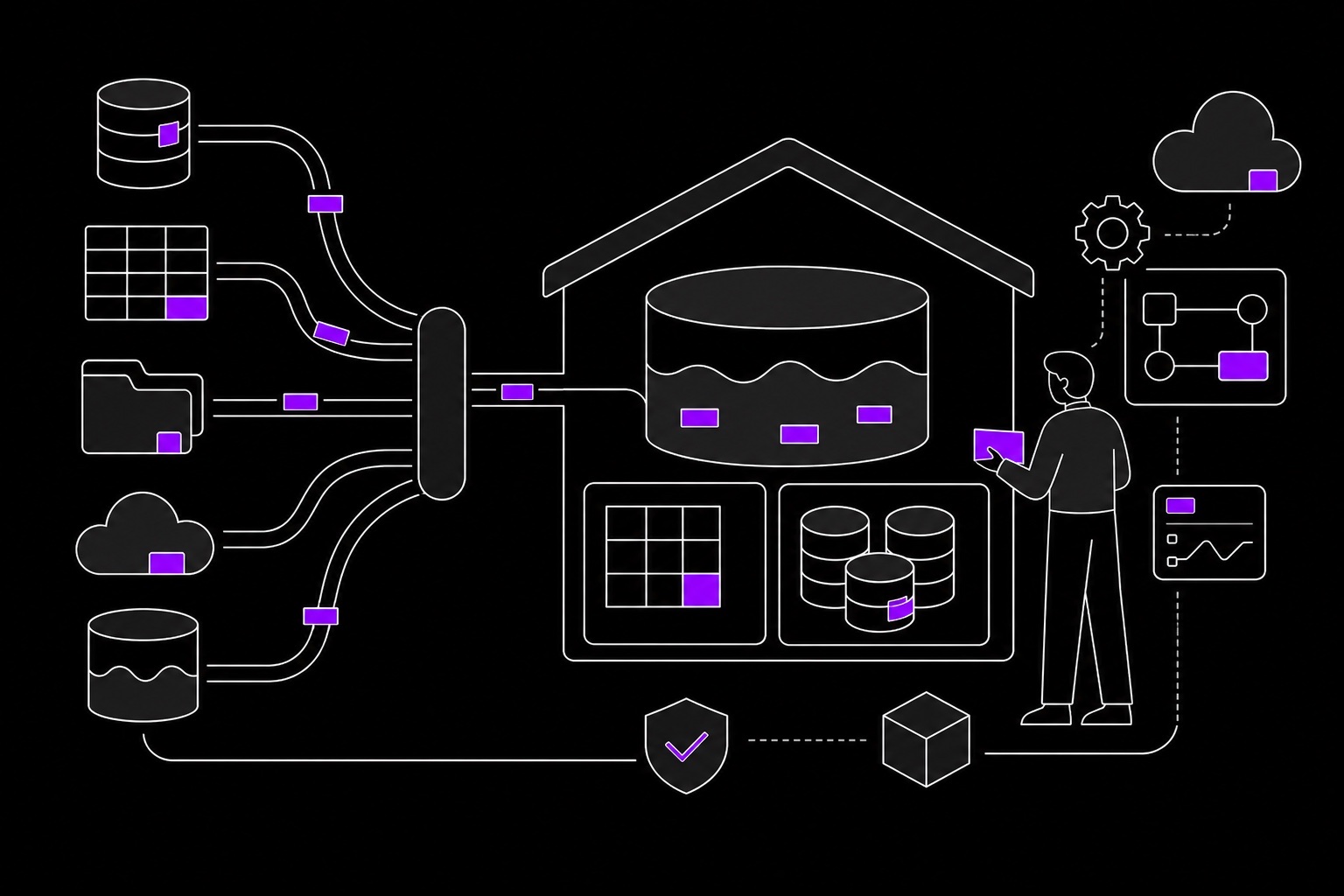

多源数据接入与标准化
接入业务库、日志、文件、API和外部数据源,建立数据字典、同步策略和采集任务监控。

![]()
服务概述
企业数据常常分散在业务系统、日志系统、文件、数据库和第三方平台中,容易出现口径不一致、任务链路不透明、质量不可控、AI应用取数困难等问题。申美从数据资产盘点、数据域划分、分层建模和数据服务出发,建设统一湖仓底座。
服务将AI赋能的测试技术咨询能力嵌入数据实施全过程,围绕采集任务、清洗规则、指标口径、数据质量、权限边界和服务接口做验证与复盘,确保数据平台上线后能稳定支撑经营分析、模型训练和智能应用。
典型场景
接入业务库、日志、文件、API和外部数据源,建立数据字典、同步策略和采集任务监控。

围绕ODS、DWD、DWS、ADS等分层体系建设主题域、明细层、汇总层和指标服务层。

梳理核心指标、维度、规则、血缘和责任人,减少跨部门口径不一致和重复建设。

配置数据开发、任务编排、依赖管理、失败重试、运行日志和链路告警,提升平台稳定性。

为RAG、训练数据、评测集、智能分析和Agent工具调用提供可控的数据接口与权限策略。

通过数据量、完整性、准确性、一致性、及时性和接口可用性测试保障上线质量。
服务组合
交付闭环
梳理系统源、数据资产、业务指标、AI应用需求和现有痛点,明确实施优先级。
设计数据分层、主题域、指标口径、权限边界、任务链路和服务发布方式。
完成数据接入、治理建模、调度配置、接口发布和链路测试,验证数据可信度。
围绕任务稳定性、质量问题、指标需求和AI应用反馈持续优化数据底座。
专家方案
带着系统清单、指标口径、数据痛点或AI应用规划来沟通,我们会帮助您判断建设优先级、实施边界与验收方式。